Node.js 아키텍쳐 톺아보기
Node.js의 아키텍쳐와 동작 원리에 대한 포스팅입니다.
📌 Overview
Runtime, Single thread, Event-driven, Non-blocking I/O, Event loop 개념 정리
📌 Runtime
Runtime은 프로그래밍 언어가 구동되는 환경이다. 크롬, 사파리 등 웹 브라우저가 javascript의 Runtime인 것이다.
🍀 과거
javascript는 브라우저에서만 동작하는 스크립트 언어였다. 역할은 DOM 조작, 동적 UI 구현, Ajax 서버 통신 등으로 한정적이었다.
🍀 현재
Node.js가 개발되며 javascript를 서버 언어로 실행할 수 있게 되었다. 역할은 웹 서버 구축, 데이터베이스 연동 등 Server-side까지 확장되었다.
Node.js의 Runtime은 아래 요소들의 조합으로 이루어진다. 각각의 역할을 살펴보자.

✨ V8 Engine과 JIT 방식
CS 관점에서 Runtime의 역할은 바이너리로 변환된 코드가 실행될 수 있게 프로세스를 구동하고, 메모리를 관리하는 것이다. Node.js는 Chrome 브라우저에 사용된 V8 Engine을 기반으로 개발되었다. (V8 Engine은 C++로 작성된 javascript 전용 고성능 웹 어셈블리 엔진이다. )
일반적인 스크립트 언어는 코드를 한 줄 단위로 읽고 실행하기를 반복하는 인터프리터 형식이다. 하지만 V8 Engine은 javascript를 바이트 코드로 컴파일하여 실행하는 방식이다.
아래에서 V8 Engine 동작 순서를 자세히 살펴보자.
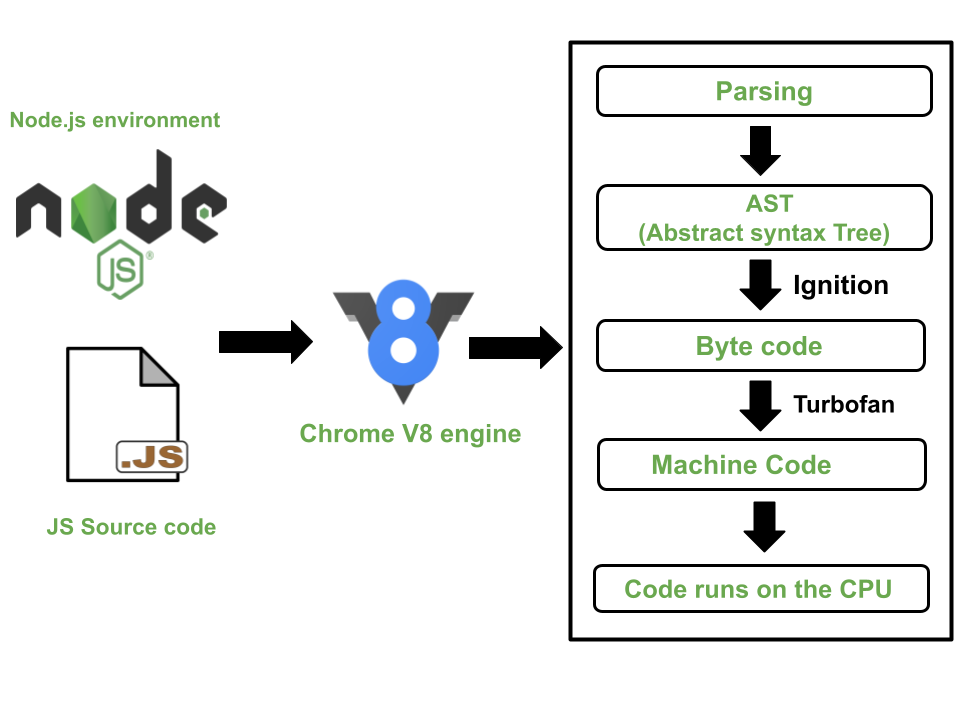
V8 Engine에서 소스 코드를Parser로 전달한다.Parser에서 소스 코드를 분석하여AST(Abstract Syntax Tree)로 변환한다.AST는 추상 구문 트리로 작성한 코드의 역할을 추상적인 노드 형식의 구문으로 표현한 것이다.Ignition(인터프리터)에서AST를 바이트 코드로 변환한다.Ignition에서 바이트 코드를 실행하여 프로그램이 동작된다.Runtime과정에서V8 Engine은 프로파일링을 통해 자주 실행되는 코드를 선별하고,TurboFan으로 전달한다. 코드 선별 시 사용하는 최적화 기법은Hidden class,Inline caching이 있다.urboFan에서 자주 실행되는 코드를 기계어로 변환한다.
위 과정을 통해 V8 Engine은 바이트 코드 전체를 기계어로 변환하는 것이 아니라, Runtime 과정에서 프로파일링을 통해 자주 실행되는 코드만 기계어로 변환한다는 것을 알 수 있다.
이러한 방식을 JIT 컴파일러 방식이라고 한다. (컴파일 방식 + 인터프리터 방식)
V8 Engine의 또 다른 특징으로는 Garbage Collection을 위해 메모리 영역을 Heap(New space, Old space), Stack으로 나누어 관리한다.
✨ libuv
libuv는 OS의 커널을 추상화하여 c++로 작성된 라이브러리이다. Single thread인 Node.js가 비동기 I/O 처리가 필요할 때, 이를 libuv가 판단하여 처리해준다. 이때에 Blocking 여부에 따라 제어권을 넘겨준다.
언제, 누가 호출하고, 어떻게 동작하는지는 아래의 Single thread에서 다룬다.
📌 Single thread
✨ Single thread의 동작 프로세스
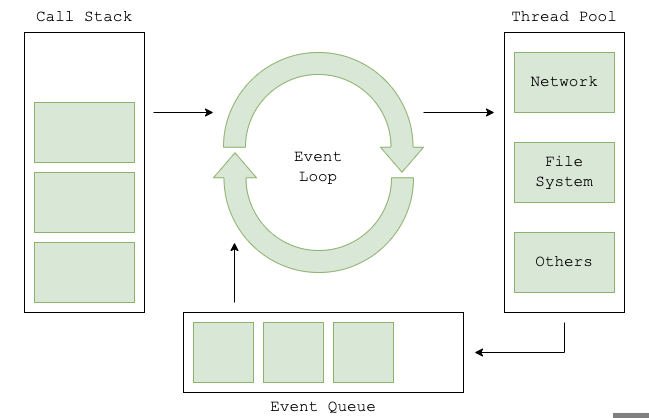
Node.js는 어떻게 Single thread로 동작할 수 있을까? 아래의 동작 프로세스를 보며 하나씩 확인해 보자
Javascript가 실행되면 작성한 코드를 해석하여 수행할 명령을Call stack에 쌓는다.Event loop가Call Stack에 쌓은 명령을 순차적으로 실행하는데, 블로킹/논블로킹 여부에 따라 제어권을 부여한다.Event loop한테 명령을 전달받은libuv(c++로 작성된 라이브러리)가 동기, 비동기를 판단한다.I/O와 같은 비동기 작업은
Thread pool에 넣고Multi thread기반으로 동작한다.
여기까지만 보면 Multi thread로 생각할 수도 있을 거 같다. 그렇다면 Node.js를 왜 Single thread로 말하는 것일까? 🤔 계속해서 프로세스를 알아보자
Thread pool서 완료된 작업의Callback함수가 존재한다면, 이를Task queue에 넘긴다.Event loop는Call Stack에 쌓인 명령이 없을 때Task queue에 있는Callback함수를 실행한다.
위 내용에서 Event loop의 역할은 Call stack에 있는 명령을 순차적으로 실행하고, 실행할 명령이 없다면 Task queue의 Callback 함수를 실행하는 것인데, 이러한 역할을 **Single thread로 동작한다. **
즉 Node.js 프로세스의 메인인 Event Loop가 Single thread로 동작한다.
📌 Event-driven
Node.js는 이벤트를 지향하는 Event-Driven으로 구성되어 있다.
✨ Event-driven의 정의
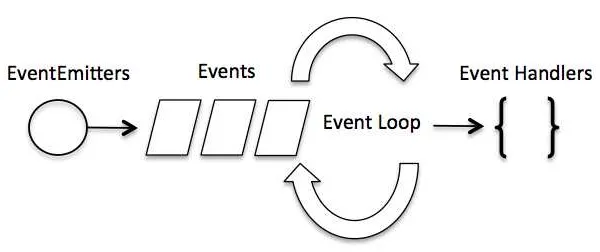
Event-driven는 이벤트가 발생했을 때 정의되어 있는 Event Handlers가 실행되는 것이다.
조금 더 자세히 알아보자면, 이벤트 발생 시 Event loop가 해당 이벤트의 Event listener를 Call stack에 쌓는다. 이후에 Single thread에서 다루었던 내용대로 순차적인 Call stack 실행이 이루어지는 프로세스이다.
아래 express 예제 코드에서 app.get 함수는 Event listener이고, 해당 이벤트가 발생했을 때 res.send가 실행되는 코드 블럭이 Event handlers이다.
const express = require('express')
const app = express()
const port = 3000
app.get('/', (req, res) => {
res.send('Hello World!')
})
app.listen(port, () => {
console.log(`Example app listening on port ${port}`)
})
✨ Event를 지향하는 이유
객체지향 프로그래밍(Object-Oriented Programming)의 이론을 예시로 들어보자. Object A에서 Obecjt B로 메시지를 전달하려면 A는 B의 참조를 가져야 하고, B의 인터페이스를 알고 있어야 한다.
// Java 코드 예시
class B {
public void displayMessage() {
System.out.println("Hello from Object B!");
}
}
class A {
private B b;
public A(B b) {
this.b = b;
}
public void sendMessage() {
b.displayMessage();
}
}
public class Main {
public static void main(String[] args) {
B b = new B();
A a = new A(b);
a.sendMessage();
A aa = new A(null);
// 참조가 없기 때문에 불가
// aa.sendMessage();
}
}
하지만 Event-driven에서는 위 내용이 적용되지 않는다. **단순하게 A는 B의 이벤트를 발생시킬 수 있다는 것이다. **
웹, 모바일 환경에서 버튼을 클릭하거나, 스크롤 할 때 이벤트를 발생시킬 수 있다. 이때 비동기적 테스크 처리로 반응 시간을 최소화하기 위해 Event를 사용하는 것이 적합하다.
✨ Event 모듈로 이벤트 핸들링하기
Node.js에는 Event 내장 모듈이 존재하는데, 아래와 같이 간단하게 이벤트를 핸들링할 수 있다. 공식 문서에서 자세한 사용 방법을 확인할 수 있다.
const EventEmitter = require("events");
// 이벤트 관리 객체 생성
const emitter = new EventEmitter();
// 'test_event' 이벤트를 이벤트 리스너에 등록
emitter.on('test_event', (name) => {
console.log(`test, ${name}!`);
});
// 이벤트 발생
emitter.emit('test_event', 'tester');
// 출력
// test, woosung!
📌 Non-blocking I/O
✨ Blocking / Non-blocking
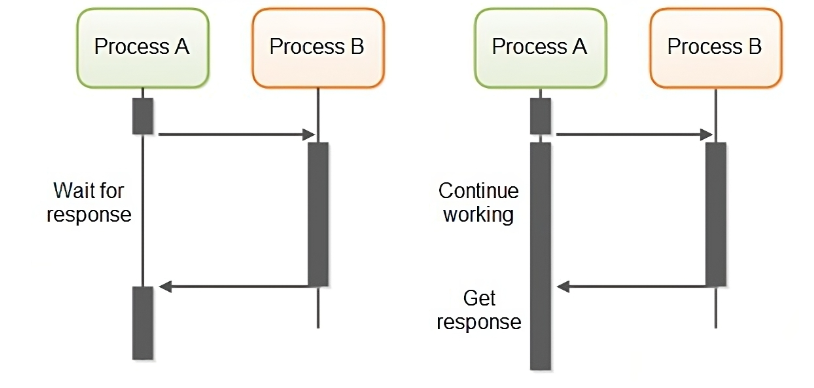
Blocking / Non-blocking은 함수 호출 시 제어권 여부에 따라 구분된다.
아래 이미지를 살펴보자. 좌측은 호출 함수에 제어권을 넘기고 기존 함수의 동작을 중단하는 Blocking 방식이다. 우측은 호출 함수에 제어권을 넘기지 않고 기존 함수를 계속 동작하는 Non-blocking 방식이다.
✨ Synchronous / Asynchronous
동기의 사전적 의미는 “동시에 진행된다”이다. 은행을 예시로 A가 B에게 만 원을 보내는 경우, A가 송금을 보낸 즉시 B는 수금 받아야 한다.
동기(Synchronous)는 호출하는 함수의 리턴(작업 완료) 여부를 지속적으로 관찰한다. 함수가 종료 시 다른 로직을 실행하거나, 리턴되는 값을 사용해야 할 경우 동기로 설계한다.
비동기(Asynchronous)는 호출하는 함수의 리턴(작업 완료) 여부를 관찰하지 않는다. 진행 중인 프로세스에 영향을 주지 않는 로직을 실행할 경우 비동기로 설계한다.
✨ Node.js Non-blocking I/O
아래는 동기로 작성된 파일 읽기 예제이다. 해당 코드에서는 파일을 다 읽을 때까지 다른 동작을 할 수 없는 Blocking인 것이다.
const fs = require('fs');
function readFileSyncExample(filePath) {
try {
const data = fs.readFileSync(filePath, 'utf8');
return data;
} catch (err) {
console.error(err);
return null;
}
}
const fileContent = readFileSyncExample('example.txt');
if (fileContent) fuPrint(fileContent);
개인적으로 Single thread인 Node.js에서는 Non-blocking으로 작성하는 게 바람직하다고 생각한다. (의도적인 Blocking 처리라면 모르겠지만..)
아래는 비동기로 작성된 파일 읽기 예제이다. 해당 코드에서는 파일 읽기 함수만 비동기로 호출한 채 다른 로직을 실행하는 Non-blocking이다. 파일 읽기 함수가 종료되면 리턴 값으로 콜백 함수를 호출한다.
const fs = require('fs');
function readFileAsyncExample(filePath, callback) {
fs.readFile(filePath, 'utf8', (err, data) => {
if (err) {
console.error('파일을 읽는 중 오류 발생:', err);
callback(err, null);
return;
}
callback(null, data);
});
}
readFileAsyncExample('example.txt', (err, fileContent) => {
if (err) console.log(err);
else if(fileContent) fuPrint(fileContent);
});
console.log('이게 먼저 출력된다');
비동기적인 작업에는 파일 Read/Write, Database 조작, API 호출 등이 있다. Node.js는 이러한 비동기 작업을 만나면 libuv의 Thread pool에 맡긴다. 이후 Thread pool에서 완료된 작업의 콜백 함수가 존재한다면 Task queue에 넣고 Event loop에 알려준다.
Non-blocking I/O은 단순한 비동기가 아니라 여러 요소들이 톱니바퀴처럼 맞물려 동작하는 Node.js 메커니즘의 결과인 셈이다.
📌 Event loop
✨ Event loop 동작 원리
┌───────────────────────────┐
┌─>│ timers │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ pending callbacks │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
│ │ idle, prepare │
│ └─────────────┬─────────────┘ ┌───────────────┐
│ ┌─────────────┴─────────────┐ │ incoming: │
│ │ poll │<─────┤ connections, │
│ └─────────────┬─────────────┘ │ data, etc. │
│ ┌─────────────┴─────────────┐ └───────────────┘
│ │ check │
│ └─────────────┬─────────────┘
│ ┌─────────────┴─────────────┐
└──┤ close callbacks │
└───────────────────────────┘
Event loop의 동작은 Timer, Pending callbacks, Idle, prepare, Poll, Check, Close callbacks 총 6개의 단계로 구분되어 있고 각 단계는 실행할 콜백을 대상으로 FIFO를 가진다.
각 단계별 역할은 아래와 같다.
Timer
setTimeout,setInterval과 같이 타이머를 설정한 콜백 함수가 실행되는 단계 delay 이후 즉시 실행되는 것이 아니라, delay 이후Event queue로 전달한다. 따라서 콜백 함수의 실행은Event queue의 내부 상황에 따라 달라질 수 있다.Pending callbacks 이전 루프에서 포함된 Input/Output 콜백, 에러 콜백을 처리한다.
Idle, prepare 내부적으로 사용, 다음 단계인 Poll로 넘어가기 전에
Event loop가 준비 상태에 있는지를 확인Poll 배정받은 시간 동안 대기 중인 콜백을
Call Stack으로 전달하고Timer의 실행 시간 제어를 담당한다. 콜백 함수가 없을 경우 Check 단계에setImmediate가 있다면Check단계로 넘어간다. 또한Timer delay대기 중에 콜백이 들어오면 즉시 처리한다.Check
setImmediate를 처리한다.Close callbacks Close 타입의 콜백 함수를 처리한다. ex)
socket.on('close', () => {});
✨ Event loop 단계 확인하기
(좋은 예제를 포스팅해 주신 분이 계셔서 참고했습니다. 😘)
아래 코드의 출력 결과를 살펴보자
setTimeout(() => { console.log("setTimeout") }, 0);
setImmediate(() => { console.log("setImmediate") });
process.nextTick(() => { console.log("process.nexttick") });
// process.nexttick
// setTimeout
// setImmediate
출력 순서가 뒤죽박죽인 이유는 각 함수의 콜백 처리가 서로 다른 페이즈와 큐에서 처리되기 때문이다.
가장 먼저 process.nexttick이 출력되는 이유는 Event loop와 별개로 nextTickQueue, microTaskQueue가 존재하기 때문이다.(process.nexttick은 nextTickQueue에서 관리) 이 두 개의 큐는 다른 페이즈로 넘어가기 전에 먼저 실행된다.
이후 순차적으로 Timer, Check 단계를 거치며 setTimeout, setImmediate이 출력된다.
📌 References
🔗 Node.js 공식 문서
🔗 Node.js 동작 원리 medium
🔗 동기/비동기, 블로킹/논블로킹 velog
🔗 이벤트 루프 medium
🔗 이벤트 루프 동작 naver